Metal基础概念——利用GPU高效计算
Categories: Study
Metal是Apple提供的一个可以让我们开发者直接和GPU对话的API。Metal在图像处理,并行计算方面通过发挥GPU的特性,极大提升了性能。
由于本人最近在一个画板需求中使用了Metal,做项目的时候由于Deadline的原因,当时并没有有系统学习。现在项目上线,回头系统学习一下Metal,顺便入门一下图像处理。本文主要是介绍一些Metal的基础概念,通过一系列项目来了解Metal。
在GPU中进行计算
通过这个例子,我们会介绍一些在所有Metal应用中都会用到的一些概念:
- 编写可以在GPU中执行的函数
- 找到一个GPU
- 通过创建管道让第一步创建的函数可以在GPU上执行
- 创建GPU可以访问的内存保存数据
- 创建command buffer并且编码GPU指令来操作数据
- 提交command buffer到command queue来让GPU执行编码的指令
既然是想利用GPU进行一些操作,我们通过下图来看一下如何使用GPU进行操作:
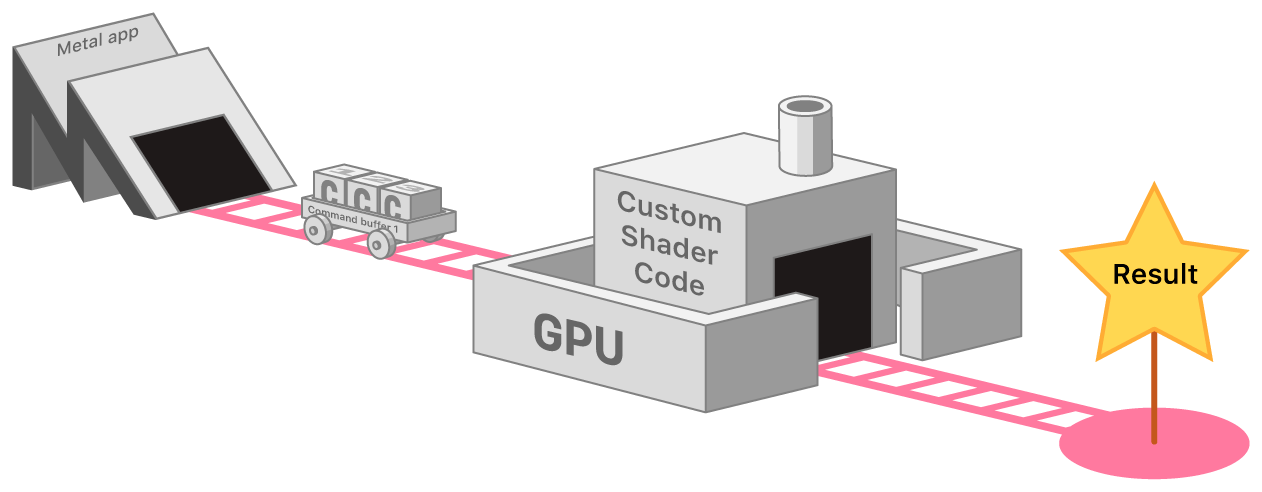 我们只需要组装command,然后提交到GPU就可以得到我们想要的结果。
我们只需要组装command,然后提交到GPU就可以得到我们想要的结果。
编写在GPU中执行的函数
通过下面两个函数,我们来看一下在GPU中计算和在CPU中进行计算的区别,我们先来看一下在CPU中把两个数组中的数相加然后把结果写到第三个数组的计算过程:
void add_arrays(const float* inA,
const float* inB,
float* result,
int length)
{
for (int index = 0; index < length ; index++)
{
result[index] = inA[index] + inB[index];
}
}
接下来我们看一下如何使用GPU实现相同的功能,在GPU中执行的函数我们统称为着色器函数(至于为什么叫着色器函数是有历史原因的,因为在GPU执行的函数大多是用来处理图像的像素的,所以叫做着色器函数):
kernel void add_arrays(device const float* inA,
device const float* inB,
device float* result,
uint index [[thread_position_in_grid]])
{
// the for-loop is replaced with a collection of threads, each of which
// calls this function.
result[index] = inA[index] + inB[index];
}
先不要管上面函数中kernel、[[thread_position_in_grid]]这些代码是什么意思(这些是Metal Shader Language的固定语法,不属于本文的讨论),只看计算过程。通过对比,我们可以发现在GPU中,我们可以并行的对每个元素进行计算,而在CPU中,我们需要遍历数组进行计算。这就是GPU强大的运算能力。我们知道,CPU擅长进行逻辑控制,串行的运算,而GPU擅长大规模的并发计算,比如上面这种简单的运算。而图像处理本身就需要大量的简单运算,所以非常适合GPU,所以一般图像处理的任务都会交给GPU去做。
找到一个GPU对象
有了上面的函数,我们如何让这个函数在GPU中执行呢?
首先,我们需要拿到一个GPU。在iOS中,我们可以通过Metal的MTLCreateSystemDefaultDevice()这个函数去拿到一个GPU的抽象对象MTLDevice。GPU对象的创建非常耗时,我们平常使用时最好使用一个单例去持有它,然后进行复用。
创建管道让函数在GPU中执行
通过上面简单的函数,我们获取到GPU的抽象对象。接下来需要配置一下我们前面写的运算函数,来让函数可以在GPU中进行执行。
当我们编译Metal应用时,Xcode会把着色器函数编译到默认的Metal library中。我们可以使用MTLLibrary和MTLFunction分别获取Metal library和着色器函数的信息。我们可以通过MTLDevice创建MTLLibrary,然后通过MTLLibrary来获取着色器函数:
_mDevice = device;
NSError* error = nil;
// Load the shader files with a .metal file extension in the project
id<MTLLibrary> defaultLibrary = [_mDevice newDefaultLibrary];
if (defaultLibrary == nil)
{
NSLog(@"Failed to find the default library.");
return nil;
}
id<MTLFunction> addFunction = [defaultLibrary newFunctionWithName:@"add_arrays"];
if (addFunction == nil)
{
NSLog(@"Failed to find the adder function.");
return nil;
}
取到着色器函数,接下来我们创建管道来配置函数,因为这里我们想使用GPU进行运算,所以,我们创建一个计算类型的管道,除了计算类型的管道还有渲染类型的管道,也就是我们经常听说的渲染管道。由于这里我们只想计算一下,所以这里我们创建一个计算类型的管道MTLComputePipelineState:
_mAddFunctionPSO = [_mDevice newComputePipelineStateWithFunction: addFunction error:&error];
创建command queue
为了把任务提交到GPU,我们需要一个command queue,对应前面图中粉色的轨道。Metal使用命令队列来安排命令。
_mCommandQueue = [_mDevice newCommandQueue];
创建数据
因为这里我们要计算两个数组元素相加对应的和,所以这里我们需要三个数组,两个相加的数组和一个存放结果的数组。GPU可以拥有自己的内存,也可以和操作系统共享内存。Metal使用MTLResource来管理内存。一个Resource表示在执行command时GPU可以访问的内存。使用MTLDeveice为它所代表的GPU创建resource。
_mBufferA = [_mDevice newBufferWithLength:bufferSize options:MTLResourceStorageModeShared];
_mBufferB = [_mDevice newBufferWithLength:bufferSize options:MTLResourceStorageModeShared];
_mBufferResult = [_mDevice newBufferWithLength:bufferSize options:MTLResourceStorageModeShared];
在这个例子中的resource是一个MTLBuffer对象,它继承自MTLResource,MTLBuffer分配的时候没有进行预先格式化。我们可以在使用的时候指定这块内存的格式。我们在分配的时候指定了一个option,MTLResourceStorageModeShared,这个option表示GPU和CPU都可以访问这块内存。为了计算两个数组相加的结果,我们需要填充_mBufferA和_mBufferB:
- (void) generateRandomFloatData: (id<MTLBuffer>) buffer
{
float* dataPtr = buffer.contents;
for (unsigned long index = 0; index < arrayLength; index++)
{
dataPtr[index] = (float)rand()/(float)(RAND_MAX);
}
}
创建command buffer
接下来我们通过command queue创建command buffer:
id<MTLCommandBuffer> commandBuffer = [_mCommandQueue commandBuffer];
创建command encoder
为了把command写到command buffer中,我们使用command encoder来编码具体类型的command。这个例子中,我们创建一个计算类型的command encoder,这个encoder编码计算过程。我们调用encoder的一些方法设置一些状态信息,比如设置管道和传入管道的参数。Encoder会把所有的状态改变和command参数写入到command buffer中。
id<MTLComputeCommandEncoder> computeEncoder = [commandBuffer computeCommandEncoder];
[computeEncoder setComputePipelineState:_mAddFunctionPSO];
[computeEncoder setBuffer:_mBufferA offset:0 atIndex:0];
[computeEncoder setBuffer:_mBufferB offset:0 atIndex:1];
[computeEncoder setBuffer:_mBufferResult offset:0 atIndex:2];
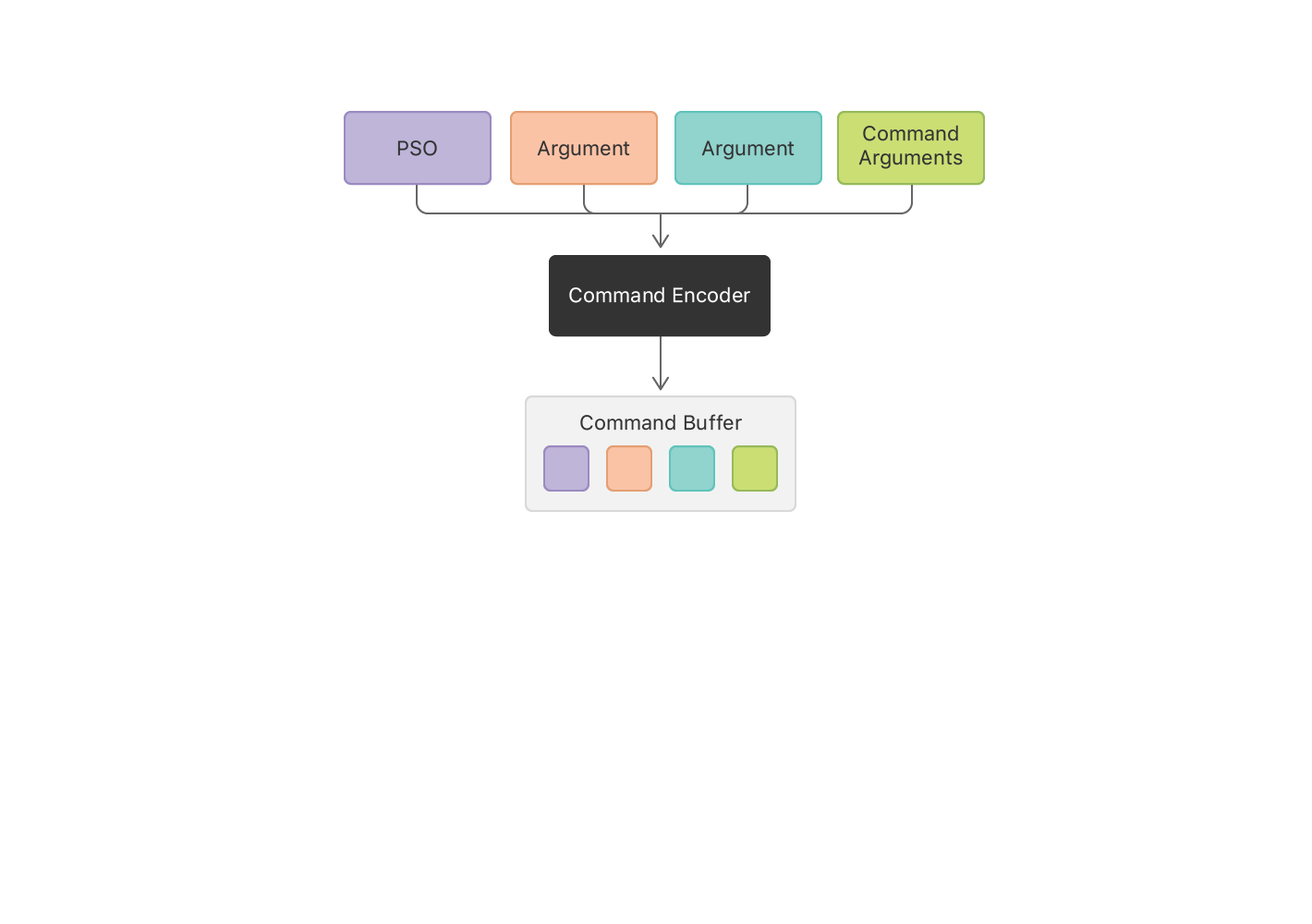 每一个计算command都会让GPU创建一组线程去执行计算,这里我们需要设置GPU分配的线程数,关于如何计算这个数字,不属于本文讨论范围,想要了解详细的计算可以看 Calculating Threadgroup and Grid Sizes 这篇文章。在这里我们先简单设置一下:
每一个计算command都会让GPU创建一组线程去执行计算,这里我们需要设置GPU分配的线程数,关于如何计算这个数字,不属于本文讨论范围,想要了解详细的计算可以看 Calculating Threadgroup and Grid Sizes 这篇文章。在这里我们先简单设置一下:
MTLSize gridSize = MTLSizeMake(arrayLength, 1, 1);
NSUInteger threadGroupSize = _mAddFunctionPSO.maxTotalThreadsPerThreadgroup;
if (threadGroupSize > arrayLength)
{
threadGroupSize = arrayLength;
}
MTLSize threadgroupSize = MTLSizeMake(threadGroupSize, 1, 1);
[computeEncoder dispatchThreads:gridSize
threadsPerThreadgroup:threadgroupSize];
描述完整个计算过程后,我们可以调用[computeEncoder endEncoding];这个方法关闭计算过程。
提交command buffer执行命令
我们可以通过调用[commandBuffer commit];这个方法,提交command buffer中的命令。我们提交后,Metal会异步的准备将要执行的命令,然后安排GPU执行命令。当GPU执行完command buffer中的所有命令后,Metal会标记这个command buffer执行完成。
我们的应用可以在GPU执行命令时做一些其他的工作,在这个例子中,我们不需要做其他工作,所以在这里我们等待GPU执行完整个command buffer:
[commandBuffer waitUntilCompleted];
Metal也支持通知的方式来通知应用,我们可以通过command buffer 的addCompletedHandler:方法添加一个handler,或者监听command buffer的status属性来在GPU执行命令时做其他工作
读取结果并验证正确定
当command buffer被执行后,GPU的计算结果存放在输出的buffer中。在一个真实的应用中,我们会从buffer中读取结果,并使用这个结果做一些事情,比如:在屏幕上显示结果或着把结果写入到文件中。 在我们这个例子中,我们仅仅读取一下结果验证一下在GPU中计算是否和在CPU中计算的是否一致。
- (void) verifyResults
{
float* a = _mBufferA.contents;
float* b = _mBufferB.contents;
float* result = _mBufferResult.contents;
for (unsigned long index = 0; index < arrayLength; index++)
{
assert(result[index] == a[index] + b[index]);
}
}
总结
通过这个例子,我们可以看到,通过编码命令的方式,可以让GPU执行一些任务。在这个例子中,我们仅仅让GPU执行了一些运算任务。让GPU执行一些其他的任务和计算任务大同小异,都是这些过程:
- 先要找到GPU对象
- 编写任务函数
- 通过编码任务把数据丢给GPU
- 提交任务。
我们可以利用GPU执行很多任务,但是一定要发挥GPU强大的运算能力。比如图像处理就是让GPU对每个像素执行一些算法,然后变换出一些滤镜效果。一定不要把CPU擅长的任务交给GPU去做,这就南辕北辙了。接下来我们将介绍一下GPU最重要的能力——渲染。
本文实例代码:代码